Ted Cahall and Moz at the old Netscape offices circa 2009
I am a huge proponent of open-source. Often I refer to using open-source software to “standing on the shoulders of giants”. Such amazing leverage to accomplish complex tasks. Software developers today are the modern alchemists stringing together pieces of the solution as the systems integrator. My tribute to open-source and Mozilla. Taken at AOL’s old Netscape offices back in the 2009 time frame.
Zabbix is an open source system monitoring and alerting tool. Even running a home data center requires monitoring the status of the equipment. When there is an issue, it needs to alert folks that things are not working correctly.
Ted Cahall uses Zabbix for Monitoring and Alerting
As I have mentioned, I run several Linux servers at home and in the AWS cloud. This is great – but it could become a nightmare to know when servers are having issues. Enter Zabbix – it is free and comes included in most Linux distributions. So it is a natural choice for monitoring Linux servers. Another great feature is that is can monitor Windows machines and Macs as well.
High Level Zabbix Overview
Zabbix is written in PHP and stores its configuration, monitoring, and alert data in a MySQL database. All of these are also free and included in Linux distributions. I would recommend adding the Zabbix repo to your package manager for each of your Linux machines. The agent version currently supported in Ubuntu 16.04 LTS is on 2.4.7 as of this blog post. Where as I selected version 3.0 in the repository. Those Linux machines are currently running version 3.0.16 and get updated as the code is updated at Zabbix.
Zabbix uses a server to collect the data and store it in MySQL. It also uses “agents” to run on each of the monitored machines. The agents are further configured to monitor certain aspects of each of the Linux machines on which they run. Zabbix monitors CPU, Memory, bandwidth, context switches, etc. right out of the box for most Linux machines without configuration.
Running in Cahall Labs
Currently I have the agents monitoring the MySQL DBs on some of the Linux servers as well as the Apache web servers and Tomcat app servers. I am also monitoring my Cassandra and Hadoop clusters. An interesting open source feature I found is the ability to monitor my various APC UPS power back-ups. Now I know if one is getting sick or when they go offline onto battery mode. This is useful when I am not at home to know the power has gone out. The agent can also be configured to monitor a Java JVM though its JMX gateway.
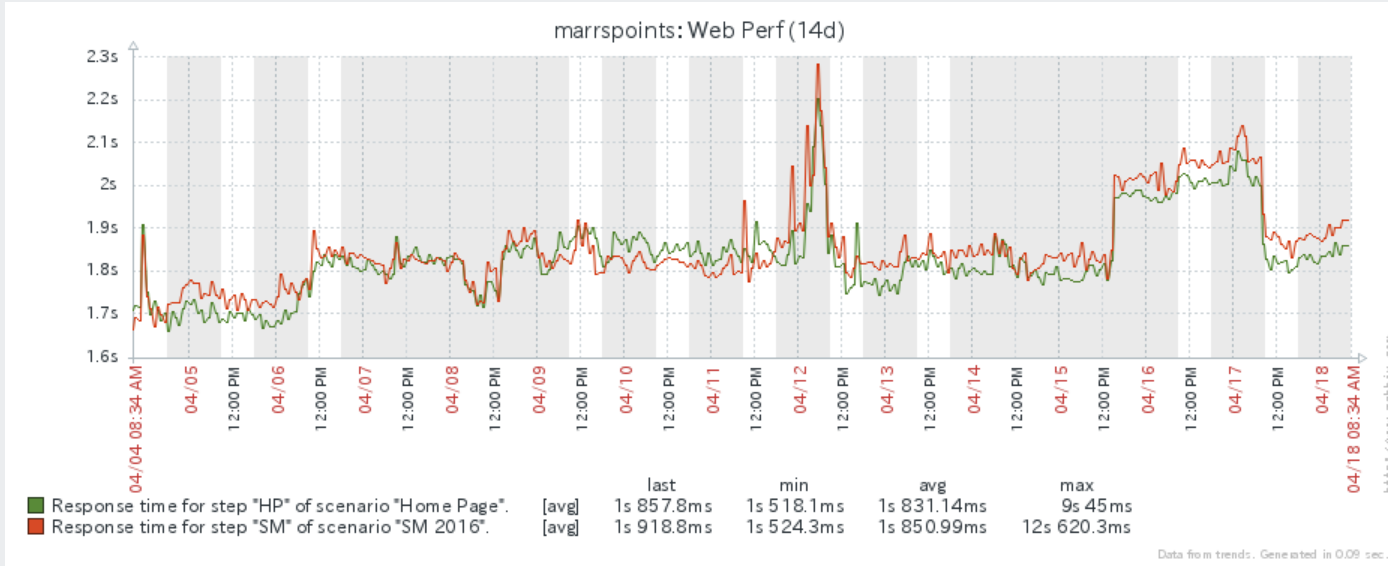
Zabbix Graph of page load performance on marrspoint.com
Zabbix can scale to thousands of servers and has a proxy feature to help offload the main server. We used Zabbix at my previous company and monitored thousands of servers in AWS as well as our private cloud. The auto-discovery feature allowed us to locate new VMs and automatically add them to the monitoring and alerting framework. Zabbix is shipping version 3.4. I have note tested beyond 3.0 at this time.
Alerts
Zabbix can alert you when something has exceeded a pre-configured threshold. For a home data center, this may be challenging as it was not clear it would simply use a Gmail account as the outbound sender. I overcame this issue by adding a SES account to AWS. This allows my Zabbix server to connect to the AWS SES server and send outbound alert emails to my personal email accounts. See sample email alert via Amazon SES below:
Zabbix Alert email sent via Amazon SES.
It also supports sending SMS text messages as alerts. However, I have not implemented that feature due to the costs of the SMS service. Email is good enough for my home data center.
Ted Cahall highly recommends Zabbix!
In summary, I find there is very little I cannot accomplish with Zabbix for my home data center (or for the Hybrid clouds at my previous employer). With some innovative thinking, I have seen everything from room temperature to number of people coming or going through an automated gate measured.
If there is a way to get the data back to a Linux server, there is a way to monitor and alert it from Zabbix. It is the Swiss Army knife of systems monitoring tools – and it is FREE!
Over the years, the definition of a geek has evolved. I guess it started with a pretty high bar (think Wozniak in a garage with wire-wrapped motherboards in the ’70s), and then dipped for a while. Does it mean running Hadoop at home now?
Build your own PCs, add a network, DNS…
For a while it simply meant you had a PC at home (probably early to mid ’80s). It then moved back up-scale to building your own PCs from components: case, motherboard, CPU, heat sink, drives, memory, etc. It moved along to the requirement of having a couple of PCs at home that shared an Internet connection. Eventually you need a few servers for file & print – and maybe a database or web server or two… Need a little internal DNS for any of that?
I have generally felt I was reasonably eligible for at least honorary geek status. At 15 years old, I wrote my first software on an IBM mini-computer back in the mid-’70s, had a PC in the early to mid-’80s (and two EECS degrees), built my own desktops and servers from components in the mid-’90s, added a server cabinet and network in the early-’00s, etc. Not sure if the fact that I have a Cisco PIX and know how to configure it from the command line counts for anything.
Home Hadoop Cluster
Using a few hours over the last 3 day weekend, I was able to bring up a Hadoop cluster on 3 CentOS nodes in my basement cabinet. Things are heading for a six node cluster. The “single-node cluster” was working in about 10-15 minutes. I have always scratched my head at the concept of a “single-node” cluster. Seems like an oxymoron to me.
Single-node “cluster” up and running – this is easy (I thought)… The hard part was getting the distributed version working. It is always some simple thing that hangs you up. In this case, it was the fact that CentOS shares the machine’s hostname with the loopback connector in the /etc/hosts file. This caused Java to bind to the loopback address (127.0.0.1) when it was listening on the NameNode and JobTracker. It worked fine in a single node configuration as the DataNodes and TaskTrackers were also looking for the loopback connector on that machine.
After tailing the logs to the DataNodes, I could see they could not connect to the NameNode. Linux netstat showed that the NameNode was binding to the loopback connector. I just was not thinking clearly enough to see that it was not also bound to the static IP address of the NameNode host. Splitting the loopback connector and static IP address into two lines in the /etc/hosts file did the trick. I thought the days of editing /etc/hosts were long over with the use of DNS.
The bar used to measure a geek
I guess the bar for being a home computer geek means running distributed processing from a rack in your basement in 2010. Now on to a little MapReduce, Pig and Hive work this weekend.
Back sometime in 2004/2005 when I was the CIO/SVP of Engineering for CNET Networks, they shot a video of me explaining, “Scaling out an Internet Architecture“. I was thinking about the current publishing system at AOL, DynaPub, that we developed in 2007 after I arrived. It was interesting after I watched the video again how close DynaPub follows the key principles described in it.
The only parts the video does not cover are:
Use of Lucene as the Search engine and SOLR as the container to hold Lucene (we invented SOLR while I was at CNET).
Use of XML over HTTP as the transport layer between the App Servers and DBs / Search engine.
Use of denormalized MySQL tables for speed
The main tool, the CMS, and its very specialized table structure for high-performance.
The AOL Publishing system is the fourth generation publishing system that I have been involved in either designing or managing. IMHO, most of the: bloated, over-designed, needlessly complex issues from previous publishing systems have been eradicated in DynaPub. It also has ZERO licensing or maintenance costs as it is all built on open-source – including the operating system – as mentioned in a previous blog post here.
Fedora Core 3 is really nice. Running it on a P4 3GHz w/ 2GB RAM. Now if I could just get the PPTP stuff from SourceForge to work I could see if the Ximian connector is worth using with a corporate Exchange account.
I know – PPTP? We also have an SSL VPN – so maybe I should use that…
I guess you can’t scribble with a keyboard very well…
This post was mostly just to try out the system and get my feet wet – so to speak. Not that anyone should read this. I am just an obscure guy whacking away on some interesting technology in the community space. I recently had the pleasure of meeting Brad Fitzpatrick, founder of Live Journal, and decided to see what the buzz was all about.
The more I poke around, the more I realize that I need to get some hobbies that involve other humans! Maybe I should go and look up the Oakland chapter of HOG now that I have lived here for over 2 years. It should not be too much trouble to ride at 9AM on a weekend day.
My big event last weekend was replacing my ATA/100 RAID 1 setup in my desktop with a SATA setup (big 150MBps!!!). Not that I wanted the extra speed, the damn controller kept crashing and corrupting the drives, and I was tired of playing with them. Now I am back to more fun projects like connecting my cable modem to my DSL line through two Cisco PIX 501s…